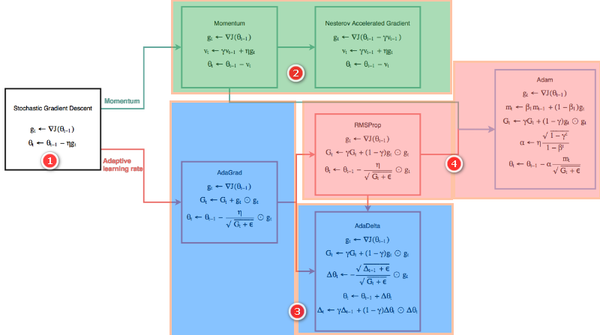
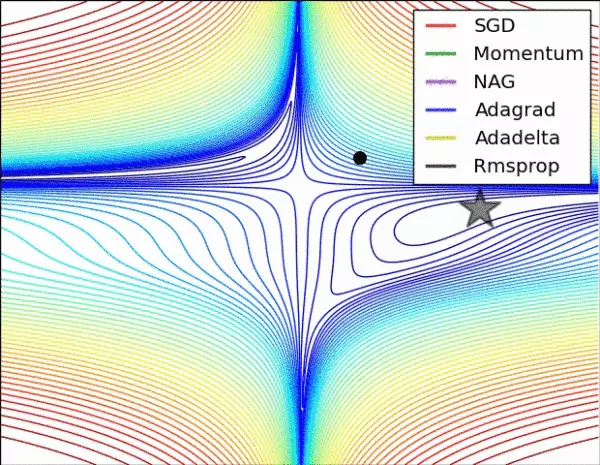
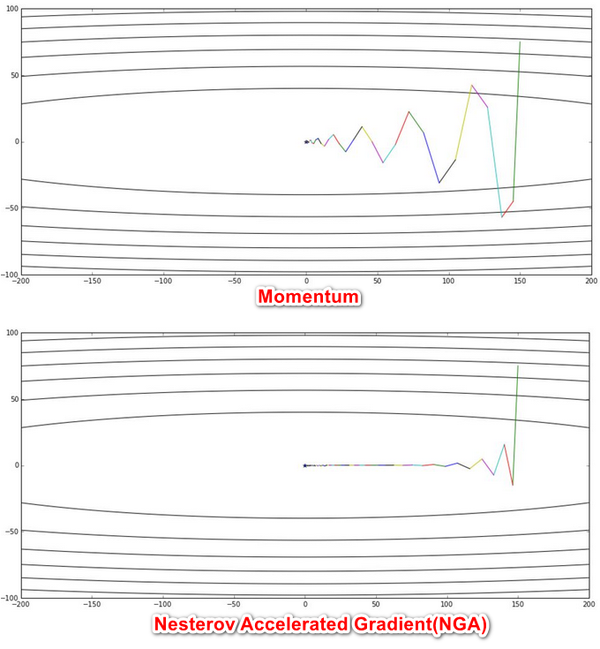
本文讲解了对神经网络进行参数更新的优化器,最基础的优化器是 w=w-rg,其中 w,r,g 表示参数、学习率和梯度,后面针对历史梯度、自适应学习率发展出不同的优化器,如 AdaGrad,Adam 等

>>> import torch
>>> from torch.autograd import Variable
>>> x=Variable(torch.ones(2,2),requires_grad=True)
>>> x,x.grad
(tensor([[1., 1.],
[1., 1.]], requires_grad=True), None)
>>> y=x+2
>>> y,y.grad # 正在访问非叶Tensor的grad属性y.grad。在backward()期间不会填充。如果确实希望为非叶张量填充.grad字段,请在非叶张量器上使用.retain_grad()
(tensor([[3., 3.],
[3., 3.]], grad_fn=), None)
>>> z=y*y*3
>>> z,z.grad
(tensor([[27., 27.],
[27., 27.]], grad_fn=), None)
>>> z.backward() # RuntimeError: grad can be implicitly created only for scalar outputs
>>> out=z.mean()
>>> out,out.grad
(tensor(27., grad_fn=), None)
>>> out.backward()
>>> x.grad,y.grad,z.grad
(tensor([[4.5000, 4.5000],
[4.5000, 4.5000]]), None, None)
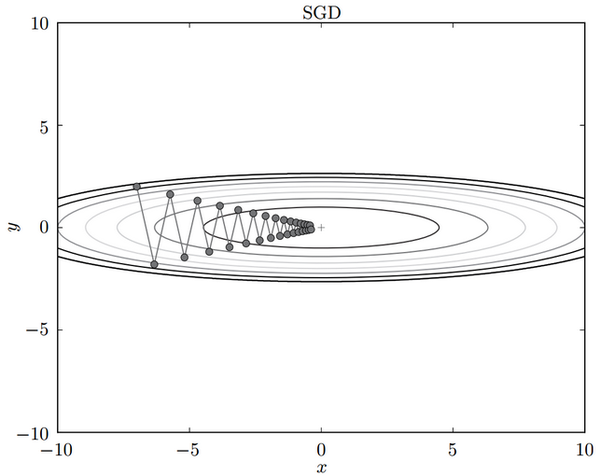
for i in range(nb_epochs):
params_grad = evaluate_gradient(loss_function, data, params)
params = params - learning_rate * params_grad

>>> import torch.optim as optim
>>> optim.Adamax(model.parameters(),lr=0.002,beta_1=0.9,beta_2=0.999,epsilon=1e-08)

本文使用 Zhihu On VSCode 创作并发布