Linux系统的性能是指操作系统完成任务的有效性、稳定性和响应速度。Linux系统管理员可能经常会遇到系统不稳定、响应速度慢等问题,例如在Linux上搭建了一个web服务,经常出现网页无法打开、打开速度慢等现象,而遇到这些问题,就有人会抱怨Linux系统不好,其实这些都是表面现象。
操作系统完成一个任务时,与系统自身设置、网络拓朴结构、路由设备、路由策略、接入设备、物理线路等多个方面都密切相关,任何一个环节出现问题,都会影响整个系统的性能。因此当Linux应用出现问题时,应当从应用程序、操作系统、服务器硬件、网络环境等方面综合排查,定位问题出现在哪个部分,然后集中解决。
随着容器时代的普及和AI技术的颠覆,面对越来越复杂的业务和架构,再加上企业的降本增效已提上了日程,因此对Linux的高性能、可靠性提出了更高的要求,Linux性能优化成为运维人员的必备的核心技能。
例如,主机CPU使用率过高报警,登录Linux上去top完之后,却不知道怎么进一步定位,到底是系统CPU资源太少,还是应用程序导致的问题?这些Linux性能问题一直困扰着我们,哪怕工作多年的资深工程师也不例外。
本文根据社区探讨,整理出企业Linux系统性能优化的7个实战经验,来自社区专家和会员分享,希望对大家有所帮助。
@zhaoxiaoyong081平安科技 资深工程师:
Linux系统的性能受多个因素的影响。以下是一些常见的影响Linux系统性能的因素:
这些因素之间相互关联,对系统性能产生综合影响。为了优化Linux系统性能,需要综合考虑并适当调整这些因素,以满足特定的需求和使用情况。
@zhaoxiaoyong081 平安科技 资深工程师:
1.CPU 性能分析
利用 top、vmstat、pidstat、strace 以及 perf 等几个最常见的工具,获取 CPU 性能指标后,再结合进程与 CPU 的工作原理,就可以迅速定位出 CPU 性能瓶颈的来源。
比如说,当你收到系统的用户 CPU 使用率过高告警时,从监控系统中直接查询到,导致 CPU 使用率过高的进程;然后再登录到进程所在的 Linux 服务器中,分析该进程的行为。你可以使用 strace,查看进程的系统调用汇总;也可以使用 perf 等工具,找出进程的热点函数;甚至还可以使用动态追踪的方法,来观察进程的当前执行过程,直到确定瓶颈的根源。
2.内存性能分析
可以通过 free 和 vmstat 输出的性能指标,确认内存瓶颈;然后,再根据内存问题的类型,进一步分析内存的使用、分配、泄漏以及缓存等,最后找出问题的来源。
比如说,当你收到内存不足的告警时,首先可以从监控系统中。找出占用内存最多的几个进程。然后,再根据这些进程的内存占用历史,观察是否存在内存泄漏问题。确定出最可疑的进程后,再登录到进程所在的 Linux 服务器中,分析该进程的内存空间或者内存分配,最后弄清楚进程为什么会占用大量内存。
3.磁盘和文件系统 I/O 性能分析
当你使用 iostat ,发现磁盘 I/O 存在性能瓶颈(比如 I/O 使用率过高、响应时间过长或者等待队列长度突然增大等)后,可以再通过 pidstat、 vmstat 等,确认 I/O 的来源。接着,再根据来源的不同,进一步分析文件系统和磁盘的使用率、缓存以及进程的 I/O 等,从而揪出 I/O 问题的真凶。
比如说,当你发现某块磁盘的 I/O 使用率为 100% 时,首先可以从监控系统中,找出 I/O 最多的进程。然后,再登录到进程所在的 Linux 服务器中,借助 strace、lsof、perf 等工具,分析该进程的 I/O 行为。最后,再结合应用程序的原理,找出大量 I/O 的原因。
4.网络性能分析
而要分析网络的性能,要从这几个协议层入手,通过使用率、饱和度以及错误数这几类性能指标,观察是否存在性能问题。比如 :
在链路层,可以从网络接口的吞吐量、丢包、错误以及软中断和网络功能卸载等角度分析;
在网络层,可以从路由、分片、叠加网络等角度进行分析;
在传输层,可以从 TCP、UDP 的协议原理出发,从连接数、吞吐量、延迟、重传等角度进行分析;
比如,当你收到网络不通的告警时,就可以从监控系统中,查找各个协议层的丢包指标,确认丢包所在的协议层。然后,从监控系统的数据中,确认网络带宽、缓冲区、连接跟踪数等软硬件,是否存在性能瓶颈。最后,再登录到发生问题的 Linux 服务器中,借助 netstat、tcpdump、bcc 等工具,分析网络的收发数据,并且结合内核中的网络选项以及 TCP 等网络协议的原理,找出问题的来源。
@zhaoxiaoyong081 平安科技 资深工程师:
在Linux环境下排查系统负载过高的原因和瓶颈,可以采取以下步骤:
综合上述步骤,可以帮助你定位系统负载过高的原因和瓶颈,并进一步采取相应的措施来优化系统性能。
需要C/C++ Linux服务器架构师学习资料加qun579733396获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享
@zhaoxiaoyong081 平安科技 资深工程师:
CPU 使用排名
ps aux --sort=-%cpu | head -n 5
内存 使用排名
ps aux --sort=-%mem | head -n 6
IO 使用排名
iotop -oP
@zwz99999 dcits 系统工程师:
查看最占用 CPU 的 10 个进程
#ps aux|grep -v USER|sort +2|tail -n 10
查看最占用内存的 10 个进程
#ps aux|grep -v USER|sort +3|tail -n 10
io
iostat 1 10看哪个磁盘busy高
@Acdante HZTYYJ 技术总监:
free是执行时间的瞬时计数,/proc/memory内存是实时变化的。
而且free会把缓存和缓冲区内存都计入使用内存,所以会导致看到的可用内存少很多。
准确值的话,建议结合多种监控指标和命令手段去持续观测内存情况。
如:htop 、 nmon 、 syssta、top等,可以结合运维软件和平台,而非站在某个时间点,最好是有一定时间的性能数据积累,从整体趋势和具体问题点位去分析。
内存只是一个资源指标,使用内存的调用才是问题根源。
@zhaoxiaoyong081 平安科技 资深工程师:
在一些情况下,通过ps或top命令查看的内存使用累计值与free命令或/proc/meminfo文件中的内存统计值之间可能存在较大差异。这可以由以下原因导致:
综上所述,ps或top命令显示的内存使用累计值和free命令或/proc/meminfo中的内存统计值之间的差异通常是由于缓存和缓冲区、共享内存以及内存回收等因素造成的。如果你需要更准确地了解进程实际使用的内存,建议参考free命令或/proc/meminfo中的统计值,并结合其他工具和方法进行综合分析
@wenwen123 项目经理:
在Linux中,可能会出现内存计算不准确的情况,导致ps、top命令中的内存使用累计值与free命令或/proc/meminfo中的内存统计值之间存在较大差异。这种差异可能由以下原因导致:
针对内存计算不准确的问题,关注共享内存是合理的。共享内存的使用可能对进程的内存使用量造成影响,但不会被ps、top等工具计算在内存使用量中。如果需要更准确地了解进程的内存使用情况,可以使用专门的工具,如pmap、smem等,这些工具可以提供更详细和准确的内存统计信息。
需要注意的是,Linux内存计算的准确性也取决于内核版本、系统配置和使用的工具等因素。在排查内存计算不准确的问题时,建议使用多个工具进行对比,并结合具体场景和需求进行分析和判断。
@zhaoxiaoyong081 平安科技 资深工程师:
虽然现代计算机的内存容量越来越大,但交换分区(swap)仍然在某些场景下具有重要的应用。以下是一些使用交换分区的常见场景:
尽管交换分区在上述场景中发挥作用,但需要注意的是,过度依赖交换分区可能会导致性能下降。频繁的交换操作可能会增加I/O负载,并导致响应时间延迟。因此,在现代系统中,通常建议合理配置物理内存,以尽量减少对交换分区的依赖,并保持足够的内存可用性。
@zhanxuechao 数字研究院 咨询专家:
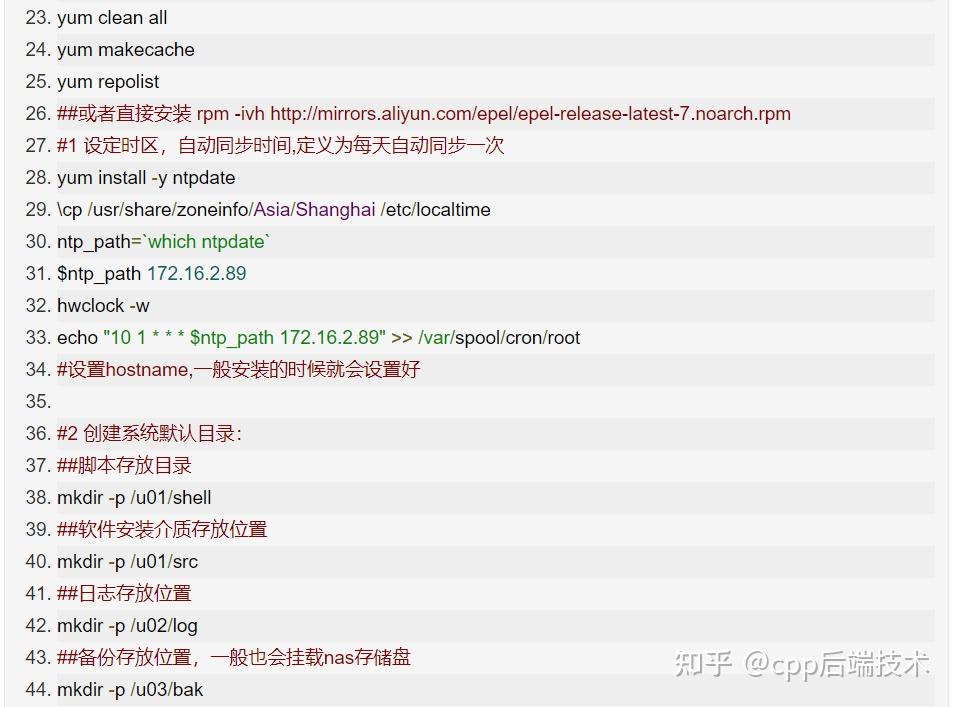
centos7-os-init.sh









@zhaoxiaoyong081 平安科技 资深工程师:
TCP 优化,分三类情况详细说明:
第一类,在请求数比较大的场景下,你可能会看到大量处于 TIME_WAIT 状态的连接,它们会占用大量内存和端口资源。这时,我们可以优化与 TIME_WAIT 状态相关的内核选项,比如采取下面几种措施。
增大处于 TIME_WAIT 状态的连接数量 net.ipv4.tcp_max_tw_buckets ,并增大连接跟踪表的大小 net.netfilter.nf_conntrack_max。
减小 net.ipv4.tcp_fin_timeout 和 net.netfilter.nf_conntrack_tcp_timeout_time_wait ,让系统尽快释放它们所占用的资源。
开启端口复用 net.ipv4.tcp_tw_reuse。这样,被 TIME_WAIT 状态占用的端口,还能用到新建的连接中。
增大本地端口的范围 net.ipv4.ip_local_port_range 。这样就可以支持更多连接,提高整体的并发能力。
增加最大文件描述符的数量。你可以使用 fs.nr_open 和 fs.file-max ,分别增大进程和系统的最大文件描述符数;或在应用程序的 systemd 配置文件中,配置 LimitNOFILE ,设置应用程序的最大文件描述符数。
第二类,为了缓解 SYN FLOOD 等,利用 TCP 协议特点进行攻击而引发的性能问题,你可以考虑优化与 SYN 状态相关的内核选项,比如采取下面几种措施。
增大 TCP 半连接的最大数量 net.ipv4.tcp_max_syn_backlog ,或者开启 TCP SYN Cookies net.ipv4.tcp_syncookies ,来绕开半连接数量限制的问题(注意,这两个选项不可同时使用)。
减少 SYN_RECV 状态的连接重传 SYN+ACK 包的次数 net.ipv4.tcp_synack_retries。
第三类,在长连接的场景中,通常使用 Keepalive 来检测 TCP 连接的状态,以便对端连接断开后,可以自动回收。但是,系统默认的 Keepalive 探测间隔和重试次数,一般都无法满足应用程序的性能要求。所以,这时候你需要优化与 Keepalive 相关的内核选项,比如:
缩短最后一次数据包到 Keepalive 探测包的间隔时间 net.ipv4.tcp_keepalive_time;
缩短发送 Keepalive 探测包的间隔时间 net.ipv4.tcp_keepalive_intvl;
减少 Keepalive 探测失败后,一直到通知应用程序前的重试次数 net.ipv4.tcp_keepalive_probes。
企业linux 性能优化从来不是一件容易的事,对于运维/开发工程师来说是绕不过去的坎,这也是运维/开发知识体系中最底层并且最难的一部分。想要学习好性能分析和优化,需要建立整体系统性能的全局观,需要理解CPU、内存、磁盘、网络的原理,掌握需要收集哪些监控的指标,以及熟练使用各种工具来分析和追踪以及定位问题。
原文地址:Linux系统性能优化:七个实战经验