说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。

贝叶斯优化器(BayesianOptimization) 是一种黑盒子优化器,用来寻找最优参数。
贝叶斯优化器是基于高斯过程的贝叶斯优化,算法的参数空间中有大量连续型参数,运行时间相对较短。
贝叶斯优化器目标函数的输入必须是具体的超参数,而不能是整个超参数空间,更不能是数据、算法等超参数以外的元素。
本项目使用基于贝叶斯优化器(Bayes_opt)优化支持向量机分类算法来解决分类问题。
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:

数据详情如下(部分展示):

使用Pandas工具的head()方法查看前五行数据:

从上图可以看到,总共有10个字段。
关键代码:

使用Pandas工具的info()方法统计每个特征缺失情况:

从上图可以看到,数据不存在缺失值,总数据量为1000条。
关键代码:
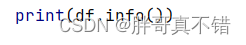
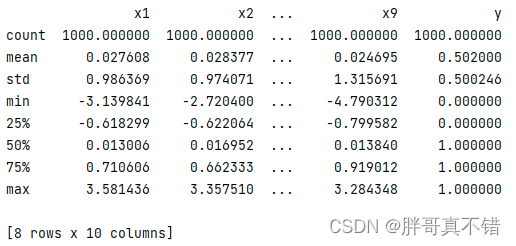
通过Pandas工具的describe()方法来来统计变量的平均值、标准差、最大值、最小值、分位数等信息:
关键代码如下:

用Pandas工具的value_counts().plot()方法进行统计绘图,图形化展示如下:
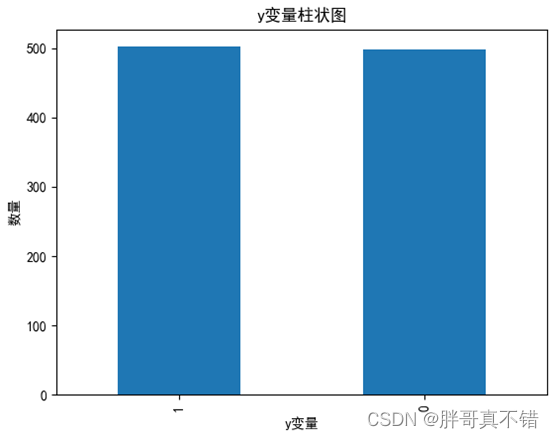
从上面图中可以看到,分类为0和1的样本,数量基本一致。
通过Matpltlib工具的hist()方法绘制直方图:

从上图可以看出,x1主要集中在-2到2之间。
通过Pandas工具的corr()方法和seaborn工具的heatmap()方法绘制相关性热力图:

从图中可以看到,正数为正相关,负数为负相关,绝对值越大相关性越强。
y为标签数据,除 y之外的为特征数据。关键代码如下:
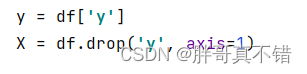
数据集集拆分,分为训练集和测试集,80%训练集和20%测试集。关键代码如下:

主要使用基于贝叶斯优化器优化支持向量机分类算法,用于目标分类。

寻优的过程信息:
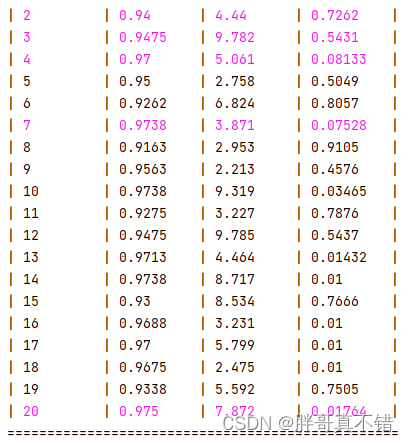
最优参数结果展示:
| 最优参数组合: C的参数值为: 7.872020435910932 gamma的参数值为: 0.01763788153507379 最优分数: 0.975 验证集准确率: 0.975 |

评估指标主要包括准确率、查准率、召回率、F1分值等等。

从上表可以看出,F1分值为0.982,说明此模型效果较好。
关键代码如下:

支持向量机分类模型的分类报告:
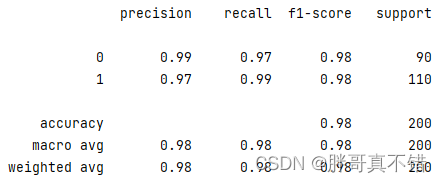
从上图可以看到,分类类型为0的F1分值为0.98;分类类型为1的F1分值为0.98;整个模型的准确率为0.98。
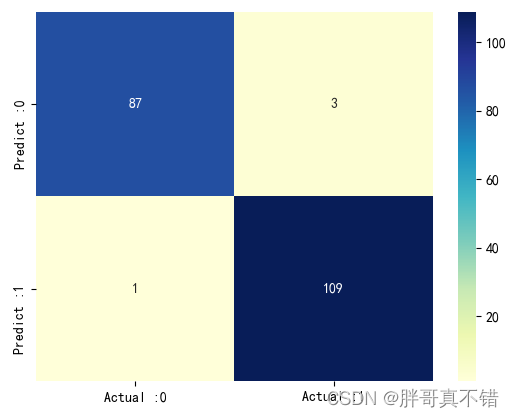
从上图可以看出,实际为0预测不为0的 有1个样本;实际为1预测不为1的有3个样本,整体预测准确率良好。
综上所述,本项目采用了基于贝叶斯优化器优化支持向量机分类模型,最终证明了我们提出的模型效果良好。