作为一个深度学习的初学者,从最基础的线性回归、Logistic回归,到更深层次的神经网络分析,在短短的学习历程中,我不止一次地叹服于种种算法在一次次发展进程中迸发出的强大的创新力与生命力。所以,在学习了几种优化算法之后,我想稍稍加以总结,以便日后学习回顾。不当之处,恳请见谅并指出。
对于给定待优化模型的参数 和目标函数
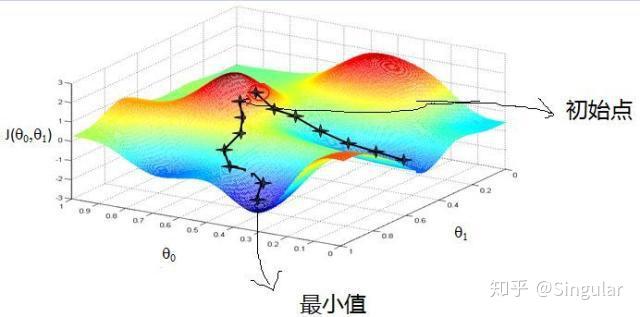
,梯度下降算法可以通过迭代收敛到目标函数的最小值。(类比于步行下山的场景)
通常可以将梯度下降算法分为三种:
用全部的训练集来进行梯度下降:
其中, 为学习率,决定了更新参数的幅度大小;m代表训练集样本数量
算法评价:
每次随机选取一个样本来进行梯度下降:
算法评价:
当样本数量(m)较大时,我们将训练集分割为小一点的子集,称为mini-batch。
假设 :m=500万,将 取出来作为第一个子训练集,以此类推,共有5000个mini-batch。
每次都用mini-batch来进行梯度下降:
其中,k为mini-batch的大小
算法评价:
所以,综合考量,MBGD算法在多数情况下更优
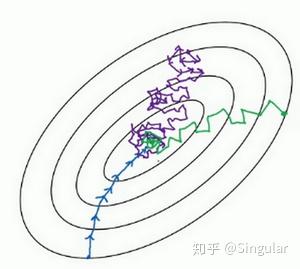
在使用梯度下降算法训练参数时,有时候会下降的非常慢,并且可能会陷入到局部最小值中,在此基础上,引入动量梯度下降算法来加快学习过程,特别是对于高曲率、小但一致的梯度,或者噪声比较大的梯度效果更佳。其主要思想在于积累了之前梯度指数级衰减的移动平均(即前面梯度的指数加权平均)。
在MBGD中加入动量:
On iteration t:
Compute on the current mini-batch:
其中,t为mimi-batch的数量;超参数 为学习率,
一般取0.9~0.99 (
的值越大,则之前的梯度对现在的方向影响越大),推荐值为0.9;
的初始值为0。
注:在动量梯度下降算法中,一般不用考虑偏差修正
算法评价:
NAG是在Momentum算法上更进一步的改良——在NAG中,我们通过计算未来位置的梯度,来代替当前位置的梯度,使得动量会在梯度达到最小值之前就开始减小,以此来提高算法的稳定性。
有Momentum算法可知:
考虑到, 很小,
所以, 即为未来权重的计算值
对未来权重计算梯度得到新动量方程:
算法评价:
目前,我只能将自适应算法粗浅地理解为使学习率随训练而改变,使其自动适应学习过程得算法。
经历过向前传播过程后,每个权重都有缓存值,用于反向传播梯度计算。Adagrade算法原理是:如果权重进行了非常大得更新,那么,该权重的缓存值将会增加,学习率将会变小,抑制其更新;反之,学习率将会增大,从而迫使参数进行较大的更新。
On iteration t:
Compute on the current mini-batch:
(缓存更新公式)
(权重更新公式)
其中,分母上的 是一个很小的值(通常取
),确保分母不为零
算法评价:
RMSprop算法针对Adagrade算法进行了改进。
On iteration t:
Compute on the current mini-batch:
(缓存更新公式)
(权重更新公式)
算法评价:
除了RMSProp算法以外,另一个常用优化算法AdaDelta算法也针对AdaGrad算法在迭代后期可能较难找到有用解的问题做了改进 。但AdaDelta算法没有学习率这一超参数。
AdaDelta算法也像RMSProp算法一样,使用了小批量随机梯度 按元素平方的指数加权移动平均变量
。在时间步0,它的所有元素被初始化为0.给定超参数
(对应RMSprop算法中的
),在时间步
,与RMSprop算法相同:
与RMSProp算法不同的是,AdaDelta算法还维护一个额外的状态变量 ,其元素同样在时间步0时被初始化为0。我们使用
来计算自变量的变化量:
最后,再使用来记录权重梯度
按元素平方的指数加权移动平均:
Adam优化算法基本上就是将Momentum和RMSprop结合在了一起。
On iteration t:
Compute on the current mini-batch:
(动量更新公式)
(缓存更新公式)
,
(偏差修正)
(权重更新公式)
注:超参数的选择—— 需要调试,
一般取0.9,
一般取0.999,
算法评价:
[1]吴恩达深度学习课程
[2]《动手学深度学习》7.7
[3]
深度学习--优化器算法Optimizer详解(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam) - 郭耀华 - 博客园[4]
梯度下降算法详解本文版权归作者所有,欢迎转载,转载请标明出处。